
QA问答系统自然语言处理领域的一个热门研究方向,它旨在构建能够理解并回答人类提出的问题的智能机器。QA系统的广泛应用领域包括法律、医疗、信息检索、文档查询、任务辅助以及常识推理等。
今天给大家「分享10篇关于QA问答系统的最新研究」,这些研究涉及到多个重要领域,包括法律QA问答、医疗QA问答、检索知识QA问答、小样本QA问答、文档QA问答、任务导向QA问答以及常识知识QA问答。这些领域不仅代表了QA系统的多样性,还体现了其潜在的广泛应用。首发: 回复:QA问答 获取所有论文!
法律QA问答
Paper:/pdf/2309..pdf
Code://lleqa
每个人都有可能面临法律纠纷,但人们对于复杂的法律知识了解并不深入,这往往会使他们变得特别脆弱。随着NLP技术的发展,通过开发自动法律援助系统可以弥补这一差距。但现有的法律问答(LQA)方法往往范围狭窄,要么局限于特定的法律领域,要么仅限于简短、无信息的回答。
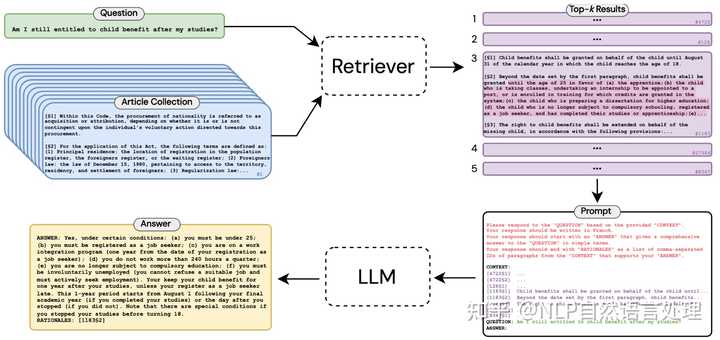
为此,本文作者提出了一种端到端的方法,「旨在利用“先检索后阅读”的管道生成任何成文法问题的长格式答案」。为了支持这种方法,作者发布了长格式法律问答 (LLeQA) 数据集,其中包含 1,868 个由专家注释的法语法律问题,并包含基于相关法律条款的详细答案。
实验结果证明了自动评估指标的良好性能,但定性分析揭示了需要改进的领域。 作为唯一全面的、专家注释的长格式 LQA 数据集之一,LLeQA 不仅有可能加速解决重大现实问题的研究,而且还可以作为评估专业领域 NLP 模型的严格基准。
医疗QA问答

Paper:/pdf/2310..pdf
医疗问答(医疗 QA)系统在协助医护人员寻找问题答案方面发挥着重要作用。然而,仅通过医学 QA 系统提供答案是不够的,因为用户可能需要解释,即用自然语言进行更多分析性陈述,描述支持答案的元素和上下文。
为此,本文研究提出了一种新方法,「为医学 QA 系统预测的答案生成自然语言解释」。 由于高质量的医学解释需要额外的医学知识,因此我们的系统在解释生成过程中从医学教科书中提取知识以提高解释的质量。
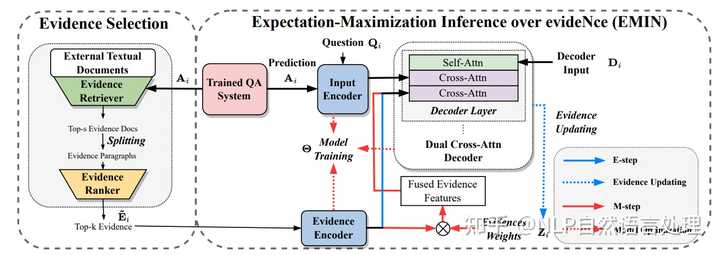
具体来说,作者设计了一种期望最大化方法,可以对这些文本中发现的证据进行推断,提供一种有效的方法来将注意力集中在冗长的证据段落上。 在数据集MQAE-diag、MQAE上证明了文本证据推理框架的有效性,并且本文方法优于最先进的模型。
小样本QA问答

Paper:/pdf/2310..pdf
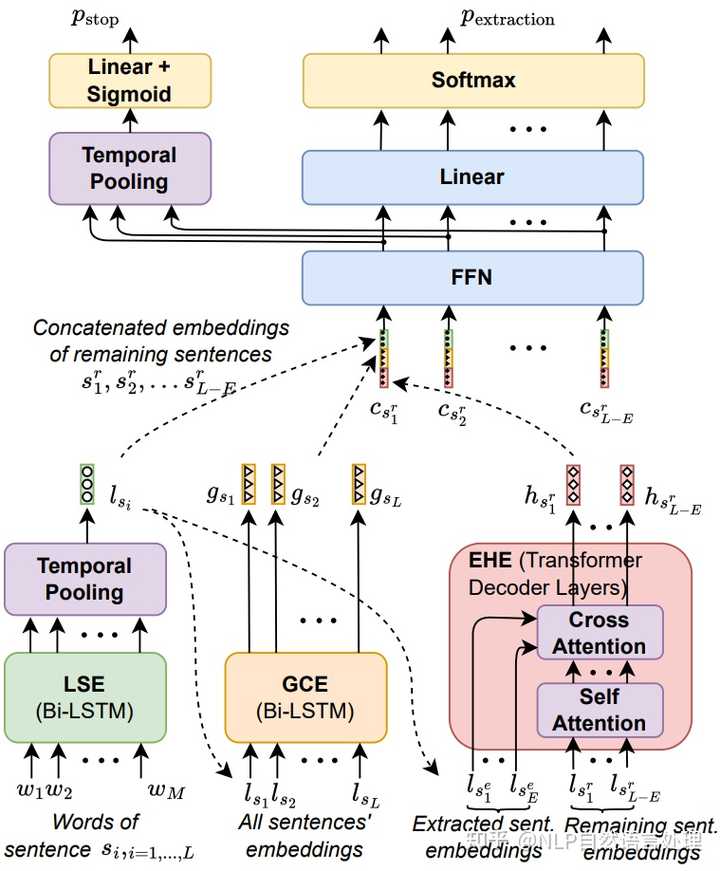
小样本问答(Few-shot QA)旨在少量训练样本的情况下,让模型给出令人满意的回答。 最新的研究进展主要依赖大型语言模型(LLM)。尽管预训练阶段已经让LLM具备了强大的推理能力,但LLM仍需要进行微调以适应特定领域,以达到最佳结果。为此,作者建议选择信息最丰富的数据进行微调,从而提高微调过程的效率。
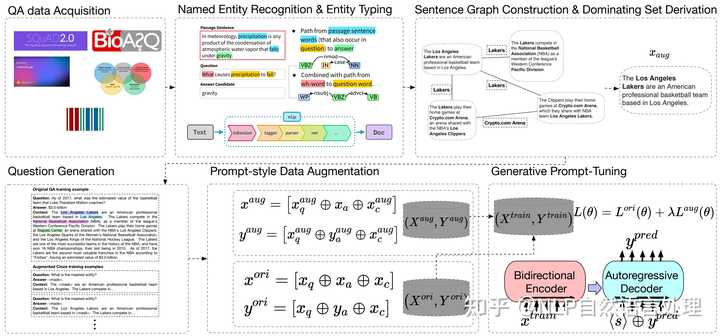
本文研究提出了「」,一个基于近似图算法和无监督问题生成的开放域QA的最小数据增强框架。 作者将原始文本转换为图形结构,以在不同的事实句子之间建立联系,然后应用图形算法来识别原始文本中最多信息所需的最小句子集。然后,根据识别的句子子集生成问答对,并在选定的句子上训练模型以获得最终模型。 实证结果表明, 能够以高效率实现与基线相当或更好的结果。
文档QA问答

Paper:/pdf/2310..pdf
Code://-DQA
本文作者提出了「-DQA,这是一种高效的文档问答 (DQA) 系统」,它利用了(一种长文档提取摘要器),通过在解析文档中的每个文本块中添加所提供的问题和问题类型的前缀,-DQA 有选择地从文档中提取文本块作为答案。
在完整文档回答任务中,与之前最先进的基线相比,这种方法的精确匹配精度提高了9%。 值得注意的是智能医疗问答系统,「-DQA 擅长解决与子关系理解相关的问题」,强调了提取摘要技术在 DQA 任务中的潜力。
宗教QA问答

Paper:/pdf/2310..pdf

随着大型语言模型 (LLM)的发展。LLM可以应用于各个领域,但应用于伊斯兰宗教领域时却与信息传输的原则相矛盾。在伊斯兰教中,严格监管信息来源以及谁可以对该来源进行解释。LLM根据自己的解释生成答案的方法类似于的概念,LLM既不是伊斯兰专家,也不是伊斯兰教所不允许的人。鉴于LLM的影响力较高,本文作者「对宗教领域的LLM进行评价」。
本文提出了问答Sirah ()数据集,这是一个根据印尼语Sirah 文献编译的新颖数据集,并使用 mBERT、XLM-R和验证该数据集,并使用 SQuAD v2.0 的印尼语翻译进行微调。 XLM-R 模型在 上得出了最佳性能,随后作者将 XLM-R 性能与 Chat GPT-3.5 和 GPT-4 进行比较。两个 版本都返回了较低的 EM 和 F1-Score。 不适合宗教领域的问答任务,尤其是伊斯兰宗教。
医疗可信QA问答

Paper:/ftp/arxiv//2310/2310.11266.pdf
为了满足医疗保健领域对先进临床问题解决工具的迫切需求,本文推出了「,这是一种基于大型语言模型(LLM)的新颖框架」。模拟人类认知过程,提供具有依据的可靠响应,利用GRADE(建议、评估、开发和评估)框架量化依据强度。
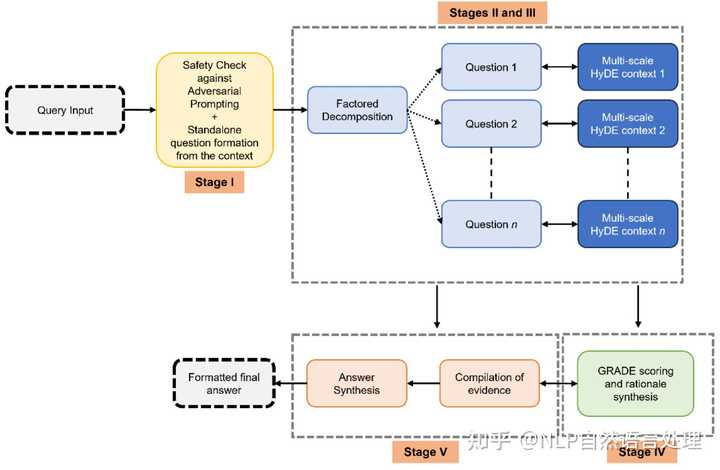
为了正确评估临床决策,需要经过临床调整和验证的评估指标。为此,作者又推出了 ,这是一个多专业临床基准,由开放式专家级临床问题组成,并由不同的医疗专业人员群体进行验证。通过要求对最新临床文献的深入理解和批判性评估, 严格评估LLMs的表现。 在各种医疗场景中均优于现有最先进的模型 Med-PaLM 2、 和 。
常识QA问答
Paper:/pdf/2310..pdf
Code:/HKUST-/
Zero-shot常识问答 (QA) 要求模型能够进行一般情况的推理。 最先进的方法一般做法是根据常识知识库 (CSKB) 构建的QA对,并对语言模型进行微调,使其能够具备更多的常识知识。但在此过程中,QA对构建过程中可能会引入来自 CSKB 的噪声,从而生成不符合预期的语法问答对,这会阻碍模型的泛化能力。
为此,本文提出了「,一种用于QA诊断和改进的动态驱动框架」。该方法分析了QA对在问答、选项两个方面上的训练动态,通过删除无信息QA对、错误标记、错误选项来简化训练检测组件。大量的实验证明了本文方法的有效性,仅使用33%的合成数据就超过了所有基线模型,其中包括等大模型。并且通过专家评估证实:该框架显着提高了 QA 合成的质量。
汽车检索增强QA问答
Paper:/pdf/2310..pdf
大型语言模型(LLM)通过遵循自然语言指令而无需对特定领域的任务和数据进行微调,表现出了卓越的性能。然而,利用LLM进行特定领域的问题回答往往会产生幻觉。此外,由于缺乏对领域和预期输出的认识,LLM可能会生成不适合目标领域的错误答案。
为此,本文提出了「」,车内检索增强会话问答系统利用了LLM的不同任务。具体而言,采用LLM来控制输入,为提取和生成回答组件提供特定领域的文档,并控制输出以确保安全和特定领域的答案。一项全面的实证评估显示,在生成自然、安全和特定于汽车的答案方面优于最先进的LLM。
知识检索QA问答
Paper:/pdf/2310..pdf

Code://
知识问答(KBQA)旨在通过检索大型知识库(KB)得出问题答案,该研究通常分为两个部分:知识检索和语义解析。但是目前KBQA仍然存在3个主要挑战:知识检索效率低下、检索错误影响语义解析结果以及先前KBQA方法的复杂性。在大型语言模型 (LLM) 时代,作者引入了「智能医疗问答系统,这是一种新型生成再检索KBQA 框架」,它建立在微调开源LLM的基础上,例如 Llama-2、 和 。
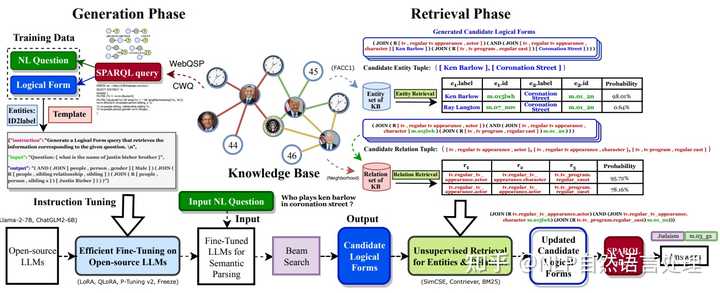
提出首先使用微调的LLM生成逻辑形式,然后通过无监督检索方法检索和替换实体、关系,这直接地改进了生成和检索。实验结果表明,在标准KBQA数据集、和 (CWQ)上实现了最先进的性能。本文研究还提供了一种将LLMs与知识图谱(KG)相结合的新范式,以实现可解释的、基于知识的问答。
任务导向QA问答
Paper:/pdf/2310..pdf
Code:///
当前,大语言模型(LLM)已用于各种自然语言处理(NLP)任务,但对于任务导向的对话系统(TODS),特别是端到端的TODS的探索仍然存在一定的局限性。为此,本文提出了「,该框架可用于Zero-Shot端到端任务导向的对话系统,无需微调即可适应不同的领域」。通过利用LLM,生成代理信念状态(proxy state),将用户意图无缝转换为动态查询,以便与任何知识库进行高效交互。
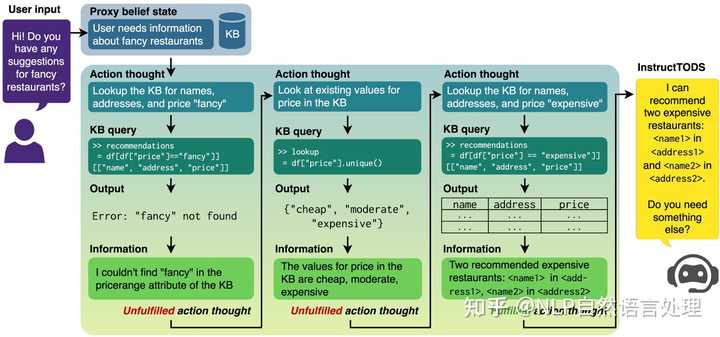
实验结果表明, 在引导对话成功完成方面达到了与完全微调的 TODS相当的性能,并且无需先验知识或特定任务数据。此外,对端到端 TODS 的严格人类评估表明, 产生的对话响应在有用性、信息性和人性方面明显优于黄金响应和最先进的TODS。此外,对TODS子任务(对话状态跟踪、意图分类和响应生成)的综合评估进一步支持了TODS中LLMs的有效性。